
Hot Chips:富士通展示百亿亿次级ARM超级计算机处理器A64FX
富士通公布了自主研发高性能基于ARM的处理器蓝图,这个名为A64FX的处理器是富士通Post-K超级计算机的“大脑”。
本周二在美国硅谷举行的Hot Chips大会上展出。Post-K是一个1000 petaflops的性能怪兽,将取代日本基于SPARC64的K超级计算机。Post-K将于2021年上线,刚刚完成一轮试验,证明了处理器的性能——至少在某种程度上说。
Post-K有望成为已经公布的、全球最快的超级计算机,届时它完全运转起来的功耗在30到40MW时。目前最快的超级计算机是美国的Summit超级计算机,该机器采用IBM POWER9和Nvidia Volta GV100处理器以及Mellanox网络设备,最大功率为188 petaflops,功耗为8.8MW。
至关重要的是,Post-K将成为一个百亿亿次级的、兼容ARM的超级计算机,这对CPU架构来说是一个重要的里程碑,目前CPU几乎用于每个人的手机、硬盘、智能卡和其他嵌入式电子产品中,并且有着驾驭笔记本电脑和服务器的梦想。
那富士通设计的超级计算机ARM处理器是什么样的?以下是我们在Hot Chips工程大会上从富士通Toshio Yoshida那里了解到的:A64FX拥有88亿个7纳米FinFET晶体管,封装有594个引脚、48个CPU核心和4个管理核心。每个芯片总共有32GB的高带宽内存(HBM2)、16个PCIe 3.0通道和1024GB/s总内存带宽,在性能方面至少达到2.7 teraflops。
52个CPU核心被分为有12个主核心外加1个管理核心的4个集群,每个集群有8GB HBM2,额定值为256GB/s,以及8MB的共享L2缓存。集群和整个芯片之间存在缓存一致性。
这些芯片是通过富士通第二代Tofu网状圆环网络相互连接的,这种互连方式可以通过10个端口将数据移入和移出每个处理器芯片,每个端口有两个通道,每个通道最大速率为28Gbps。
 A64FX的缓存层次结构和速度,每个集群有12个计算核心和1个管理核心,4个集群到1个芯片。来源:富士通
A64FX的缓存层次结构和速度,每个集群有12个计算核心和1个管理核心,4个集群到1个芯片。来源:富士通
CPU核心只支持64位(没有32位模式),采用Armv8.2-A指令集,支持ARM的512位宽SIMD SVE,意味着芯片可以在硬件中处理矢量和矩阵计算,这对于超级计算机和机器学习应用来说是必须的。此外它还支持16位和8位整数数学,以及通常的浮点精度(FP16、32和64),对AI推理代码很有用处。
我们得知,A64FX是一种超标量无序执行的“怪兽”,也是第一款Armv8.2-A设计。完成32位和64位Arm组装编程的人会知道,该架构具有固定宽度指令,通常每个指令一个操作,是经典的RISC思想学派。有趣的是,通过实施SVE,A64FX为四操作数融合乘法加法指令(FMA4)提供了一个指令前缀——这是一个非常有用的操作——多少让我们想起了x86指令前缀。
要执行计算r0 = r3 + r1 * r2,你要使用两个指令,这两个指令在预解码阶段合并为一个,尽管开始是两个指令,但仍在一个步骤中执行。这些是:
 每个CPU核心的执行单元可以同时处理2个512位SIMD操作。输入数据打包成512位,并一次性进行处理——就像英特尔在其服务器部件上的AVX512操作一样。因此,你可以输入4个8位值,4个相应的8位系数或权重,它们相乘得到四4个答案,然后添加到32位偏移量,并写入寄存器。
每个CPU核心的执行单元可以同时处理2个512位SIMD操作。输入数据打包成512位,并一次性进行处理——就像英特尔在其服务器部件上的AVX512操作一样。因此,你可以输入4个8位值,4个相应的8位系数或权重,它们相乘得到四4个答案,然后添加到32位偏移量,并写入寄存器。
富士通认为,当做8位整数运算时A64FX可以达到21.6 TOPS(万亿或每秒万亿次运算); 做16位整数运算时可以达到10.8 TOPS;做32位整数运算时可以达到5.4 TOPS;64位时是2.7 TOPS,全部都是执行整数SIMD。据称,A64FX至少比富士通之前的超级计算机处理器——SPARC64 XIfx——在运行高性能计算和人工智能负载时快2.5倍。
相比之下,Nvidia用于服务器的P4和P40加速器时钟频率为22和47 TOPS(8位整数)。
L1缓存有一个组合的收集机制,可以获取数组中的连续元素并将其复制到寄存器中。因此举例来说,你可以使用它将存储器中的8个字节转换为一个64位寄存器,每个字节插入寄存器中自己的字节位置。指令引擎以230GB/s的速度读取每核四路64KB L1数据高速缓存,并以115GB/s的速度写回。L2共享缓存以115G/s的速度提供数据,并以57GB/s的速度接收数据。
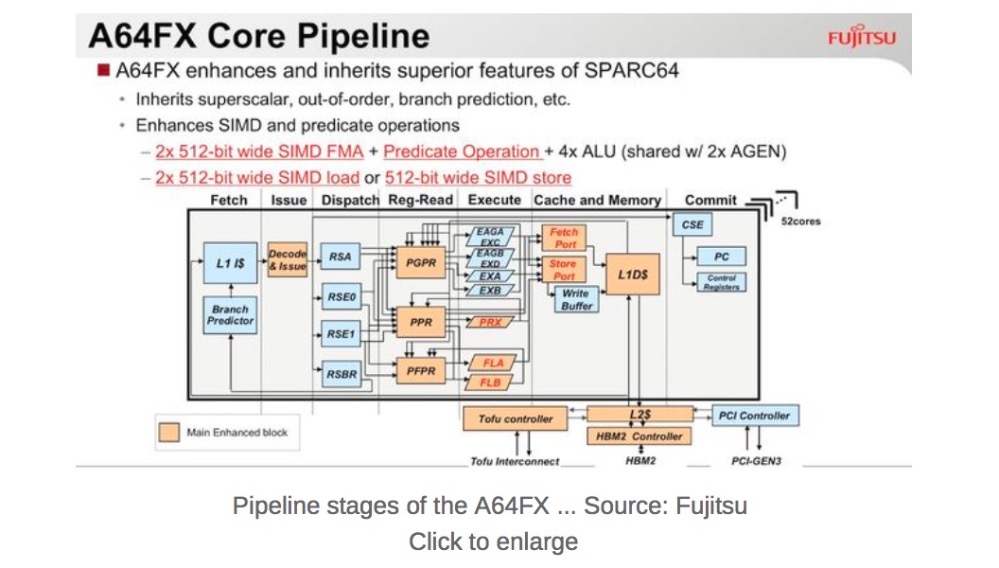 A64FX的管道阶段。来源:富士通
A64FX的管道阶段。来源:富士通
每个芯片的功耗使用请款是以每毫秒为单位进行监控和控制的,并且每个核心的速率低至纳秒级。富士通称,A64FX具有大型机级的弹性,所有缓存都有ECC或重复数据删除功能,执行单元内的奇偶校验,如果检测到出错,就会重试指令,Tofu互连链路上的错误恢复以及针对芯片的总共128000个错误检查器。
整个shebang字符串行运行Linux,基于Lustre的分布式文件系统和非易失性存储器用于加速文件输入输出。工具链支持C、C ++和Fortran编译器、MPI、OpenMP、调试器以及其他工具和语言。
你会注意到没有第三方加速器:它是纯粹的ARM,这就是富士通的方式,目的是设计一个运行超级计算机类型应用(模拟、科学实验分析、机器学习和其他数字运算)的芯片,具有比通用CPU更高的每瓦性能。
遗憾的是,Yoshida并不想谈论时钟频率和单个芯片的功耗。该机器距离完成还有几年的时间,所有规格和实施细节尚未确定或者透露。“我们将继续开发ARM处理器,”他这样表示。
好文章,需要你的鼓励


Mistral AI公布环境审计报告揭示AI隐藏成本
法国AI初创公司Mistral AI发布了首个大语言模型全面生命周期评估,量化了AI的环境代价。其Mistral Large 2模型训练产生20,400吨二氧化碳当量,消耗281,000立方米水。运营阶段占环境影响85%,远超硬件制造成本。研究表明地理位置和模型大小显著影响碳足迹,企业可通过选择适当规模模型、批处理技术和清洁能源部署来减少环境影响。这一透明度为企业AI采购决策提供了新的评估标准。

上海AI实验室的新突破:让你用键盘控制的虚拟世界探险家YUME
上海AI实验库推出YUME系统,用户只需输入一张图片就能创建可键盘控制的虚拟世界。该系统采用创新的运动量化技术,将复杂的三维控制简化为WASD键操作,并通过智能记忆机制实现无限长度的世界探索。系统具备强大的跨风格适应能力,不仅能处理真实场景,还能重现动漫、游戏等各种艺术风格的虚拟世界,为虚拟现实和交互娱乐领域提供了全新的技术路径。

认为AGI和AI超级智能将揭示生命真谛的想法
许多人认为一旦实现通用人工智能(AGI)和人工智能超级智能(ASI),这些高度先进的AI将能够告诉我们人生的真正意义。然而,巅峰AI可能无法明确回答这个史诗般的问题。即使AI拥有人类所有知识,也不意味着能从中找到生命意义的答案。AI可能会选择提供多种可能性而非绝对答案,以避免分裂人类社会。

上海AI实验室重磅发布:让机器自己学会编程验证,告别人工标注的时代
上海AI实验室研究团队开发了革命性的AI编程验证方法,让大语言模型能够在最小人工干预下自动生成和验证程序规范。该方法摒弃传统的人工标注训练,采用强化学习让模型在形式化语言空间中自主探索,在Dafny编程验证任务上显著超越现有方法,为AI自主学习开辟新道路。
2018
08/24
09:44
分享
点赞

一颗192核的Arm服务器CPU
Arm技术媒体分享日:探索AI时代的计算前沿与生态布局
引领AI时代计算新纪元:Arm终端计算子系统重塑智能设备性能边界
Arm亮相COMPUTEX 2024: 预计2025年底超过1000亿台Arm设备可用于AI
Arm推出人工智能优化的Arm终端计算子系统以及新的Arm Kleidi软件,重新定义移动端体验
《日经亚洲》报道Arm明年将推首款产品进军人工智能芯片市场
让智能手机与PC具备领先的AI计算性能 下一代Arm Cortex-X内核信息“浮出水面”
Arm的使命是助力应对AI 无止尽的能源需求
能效和定制化将推动ARM在人工智能领域发挥关键作用
加速边缘AI部署 Arm推出Ethos-U85 NPU和Corstone-320
